爬虫小结
爬着爬着,就进局子里了...........
前言
在刚开始学python的时候就对这一方面非常感兴趣,但是奈何当时实力太水,跟着mooc学了很久,也才刚刚把基础学完,连数据处理都不太会,而且在这次之前又学了一下c,三斤八两,啥都不会,刚开始在中国慕课mooc上跟着嵩天老师学习,发现他好多的例子都已经过时,很多之前能够爬取的网站现在已经无法爬取,当然也不是没有办法,只是我太水了,BeautifulSoup库也一直没有搞懂,因为我对html并不是很了解,于是乎chrome的审查工具用得也不是太好,刚好上次尝试了今日校园自动签到后,在优化那位大佬的程序时,我突然意识到里面很多的语法其实很有逻辑和体系,而他之所以能写出300多行的代码来造福广大学子,在于他强调的:“我模拟的整个今日校园的过程”,而这个过程,就是抓包,于是我在突然想起了点什么,我的fiddle,好像躺在我的电脑中睡了很久😂,后来在这个过程我想起的很多去年CTF教我的一些知识(但是我没学会),还有那个可爱的nmap
爬虫
有道翻译
打开开发者工具后,我们对我们输入的字符“are you ok”,进行抓包,马上我们可以看到,其他的数据都是以图片的形式,而这里是一个多次出现,但是咋们不清楚的包,于是我们查看一下headers,发现是post方法,
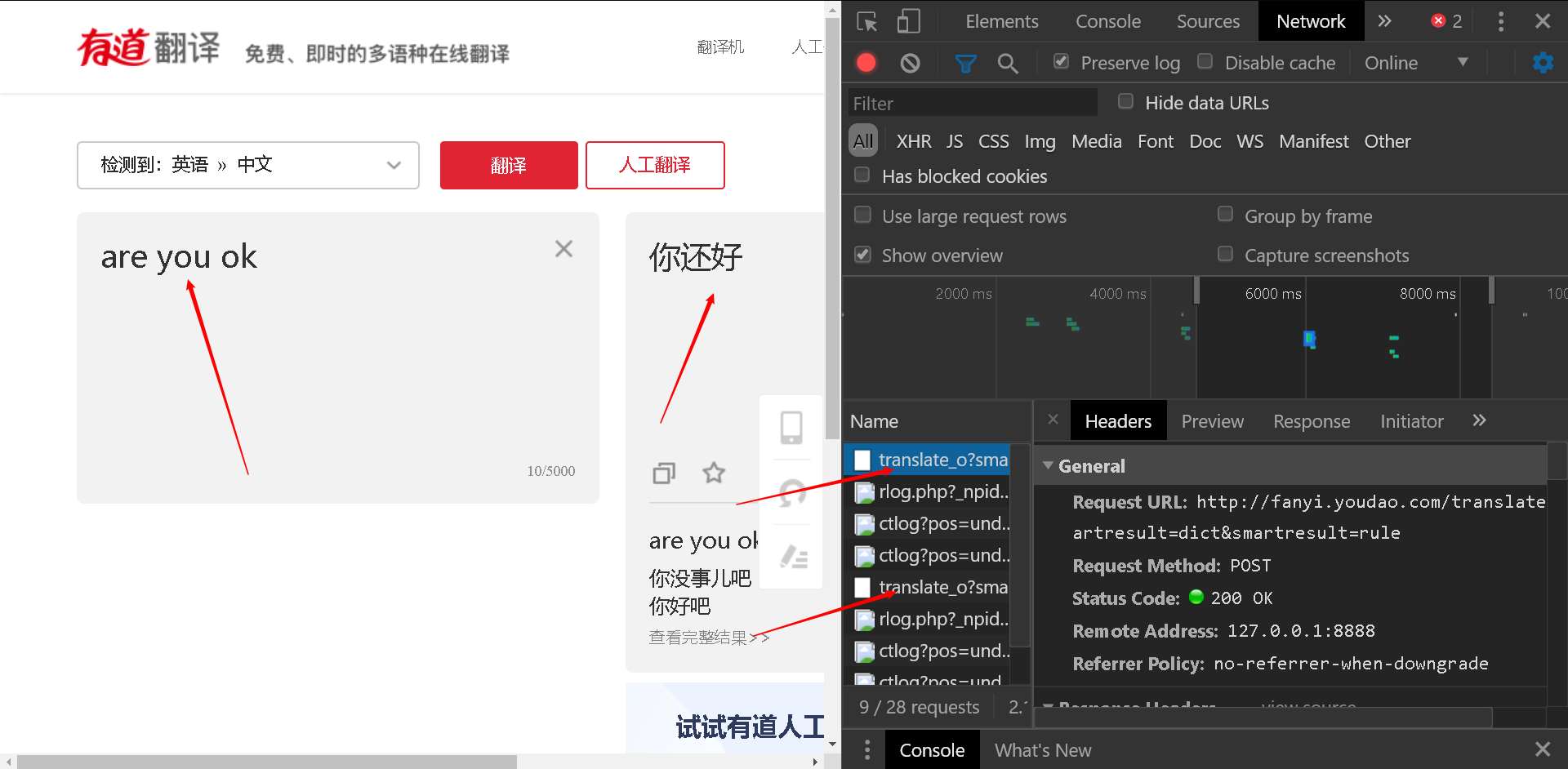
观察Response ,发现里面刚好有我们想要的翻译结果,于是我们只要模拟浏览器去post,然后接受相应的json数据格式,即可!

我们首先还是要去看看这个post到底上传了什么form,然后这个header到底有什么要求,首先我们观察到了这个post的地址,但这里还是有坑,这是我后面的才发现的

观察webform,把它复制粘贴到代码就可以了

但是,这里有问题了:返回值有问题,百度一下,原来那个网址有问题,只能是http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule ,_o必须要被去掉 (这里是因为有道翻译的反爬虫机制)

把url改回来,再使用json的loads函数将数据转化为字典,提取出翻译就可以了,把它改的更人性化一点,例如接受输入可以多次输入,ok,这样咋们就实现了在cmd里翻译啦!


百度图片
 如图,爬取百度图片结果的所有图片,打开开发者工具,找出图片的实际地址,多观察几张,发现这个图片都在
如图,爬取百度图片结果的所有图片,打开开发者工具,找出图片的实际地址,多观察几张,发现这个图片都在<li>标签下


这时候我们可以选择BeautifulSoup或者re正则表达式,我使用了正则表达式,提取了所有的图片url,然后把这些链接全部get即可

这样就把一页的图片全部爬取下来啦,至于为什么只有把29张,是因为百度的图片加载使用了一种叫做Ajax技术,这样的话只能采取别的方法去爬取了,我现在还不知道如何突破😂

B站视频
刚好看到B站也有相关的学习视频,方法和上面的第一个第二一样,算是两者的综合吧,需要用到re(或者BeautifulSoup),设置好请求头,我自己做这个的时候,并没有添加很多对用户界面很友好的东西,但是还是去借鉴了一下前辈的经验,弄了个进度条
先下载这个压缩包
整体来说网速还是不是错的,我家是100兆的光纤,由于我的电脑离路由器比较远,网速只有这个效果,但是这个这个爬虫还是能够把我家的网爬满。


先把压缩包解压,一个放在D盘,一个放在桌面,第二,配置环境变量,再上方的用户变量的PATH中双击然后打开


找到D盘里的刚刚放进去的ffmpeg 打开bin 目录,把那个文件夹地址复制,例如我的是D:\ffmpeg-N-100892-g44e27d937d-win64-lgpl-shared-vulkan\bin粘贴到新增的Path中,然后一路ok,添加完用户变量,就可以使用软件了


软件的使用很简单,它的界面只是一个终端界面,你只要将B站视频网址粘贴,回车即可,默认视频的最高画质(不开会员的情况下)😂

为什么要把它添加到环境变量呢,因为B站爬取的视频其实是分音频和视频的,而ffmpeg是一个音视频处理软件,我是先将音频(1.mp3)和视频(2.mp4)分别爬取,然后用ffmpeg把它们拼接在一起(自动删除1.mp3和1.mp4),我找了很多教程,实在不会把ffmpeg源代码整合到我的代码中,于是就需要它的存在,并且要把它配置为用户变量,否则